(换肤)
语言:

文章编号:10740时间:2024-09-29人气:
快速排序是一种高效的排序算法,其核心思想是通过一趟排序将数组分割成两部分,一部分所有数据小于另一部分,然后递归地对这两部分进行排序。 理解这个过程的关键在于递归调用自身。

首先,我们从一个待排序的数组 A[1]...A[N] 出发。 选择一个基准元素,通常选择第一个元素作为起点,将其称为 X。 接着,设立两个指针 I 和 J,分别指向数组的起始和结束。
一趟快速排序 如此进行:从 J 开始向前搜索,遇到小于 X 的元素就将其与 I 位置的元素交换;同时,从 I 向后搜索,找到大于 X 的元素进行交换。 这个过程会一直持续,直到 I 和 J 指针相遇。
值得注意的是,快速排序的 递归特性:当划分完成后,对左右两部分再次执行相同的排序步骤,直到每个子数组只剩下一个元素或为空,递归结束。 这是一种典型的分治策略,每一次递归都将问题规模缩小,直至达到基本情况。
然而,快速排序并非 稳定排序,相同元素的相对位置可能会在排序过程中改变。 这源于交换操作,可能会打乱相同值的顺序。
在代码实现中,递归调用的伪代码如下:
总的来说,快速排序的递归过程如同一场精密的舞者编排,每个元素都在有序与无序之间优雅地切换,直至整个序列井然有序。 希望这篇文章能帮助你深入了解快速排序的递归之美。
常见排序算法(冒泡,选择,快速)的C语言实现要实现这几种算法的关键是要熟悉算法的思想。
简单的说,冒泡排序,就如名字说的,每经过一轮排序,将最大的数沉到最底部。
选择排序的思想是将整个数列,分为有序区和无序区。
每轮排序,将无序区里的最小数移入到有序区。
快速排序的思想是以一个数为中心,通常这个数是该数列第一个数,将整个数列分为两个部分,一个部分是大于这个数的区域,一个部分是小于这个数的区域。
然后再对这两个部分的数列分别排序。
如果将数列分为两个部分是通过,一方面从后向前的搜索,另一方面从前向后的搜索来实现的。
具体的参考后面的来自网络百科的文档。
从这几个简单的排序算法上看,有几个特点:冒泡排序是最简单的,也是最稳定的算法。
选择排序不太稳定,但是效率上较冒泡还是有较大的提升。
其实在分析的过程中就能发现,选择排序和冒泡排序相比,中间少了很多的交换过程,和比较的次数,这个应该是时间较少的原因。
选择排序能够满足一般的使用。
当比较的数超过以万为单位时,选择排序也还是要一点时间的。
快速排序据说是最快的。
这个可以从思想上看的出来。
,当记录较多的时候,快速排序的比较循环次数比上面2个都要少。
但是在具体的实现过程中,并不见得如此。
这是因为递归效率的低下导致的。
当然,估计在实际使用过的过程,快速排序估计都会使用非递归操作栈的方式来实现。
那样应该会效率高伤不少。
估计我会在后期出一个快速排序的非递归实现来真正比较它们3个性能。
在下面的程序中,可以通过调高N的数字就能看的出来冒泡排序和选择排序性能的差异。
在N较小,大概几百的时候,是看不出来的。
N较大的的时候,比如N=1000或者N=的时候,快速排序的递归实现就会卡死在那里了,出不了结果。
以下是具体的代码:/*** 常见排序算法比较 */#include
快速排序思想:通过对数据元素集合Rn 进行一趟排序划分出独立的两个部分。 其中一个部分的关键字比另一部分的关键字小。 然后再分别对两个部分的关键字进行一趟排序,直到独立的元素只有一个,此时整个元素集合有序。 快速排序的过程,对一个元素集合R[ low ... high ] ,首先取一个数(一般是R[low] )做参照 , 以R[low]为基准重新排列所有的元素。 所有比R[low]小的放前面,所有比R[low] 大的放后面,然后以R[low]为分界,对R[low ... high] 划分为两个子集和,再做划分。 直到low >=high 。 比如:对R={37, 40, 38, 42, 461, 5, 7, 9, 12}进行一趟快速排序的过程如下(注:下面描述的内容中元素下表从 0 开始):开始选取基准 base = 37,初始位置下表 low = 0 , high = 8, 从high=8,开始如果R[8] < base ,将high位置中的内容写入到R[low]中, 将high位置空出来, low = low +1 ;从low开始探测,由于low=1 , R[low] > base ,所以将R[low]写入到R[high] , high = high -1 ;检测到low < high ,所以第一趟快速排序仍需继续:此时low=1,high=7,因为 R[high] < base ,所以将 R[high] 写入到到R[low]中,low = low + 1;从low开始探测,low = 2 , R[low] >base ,所以讲R[low]写入到R[high],high=high-1;继续检测到 low 小于high此时low=2,high=6,同理R[high] < base ,将R[high] 写入到R[low]中,low=low+1;从low继续探测,low = 3 , high=6 , R[low] > base , 将R[low]写入到R[high]中,high = high-1;继续探测到low小于high此时low=3,high=5,同理R[high] < base,将R[high]写入到R[low]中,low = low +1;从low继续探测,low = 4,high=5,由于R[low] > base , 将R[low]写入到R[high]中,high = high -1 ;此时探测到low == high == 4 ;该位置即是base所在的位置,将base写入到该位置中.然后再对子序列Rs1 = {12,9,7,5} 和 Rs2={461,42,38,40}做一趟快速排序,直到Rsi中只有一个元素,或没有元素。 快速排序的Java实现:private static boolean isEmpty(int[] n) {return n == null || == 0;}// ////////////////////////////////////////////////////** * 快速排序算法思想——挖坑填数方法: * * @param n 待排序的数组 */public static void quickSort(int[] n) {if (isEmpty(n))return;quickSort(n, 0, - 1);}public static void quickSort(int[] n, int l, int h) {if (isEmpty(n))return;if (l < h) {int pivot = partion(n, l, h);quickSort(n, l, pivot - 1);quickSort(n, pivot + 1, h);}}private static int partion(int[] n, int start, int end) {int tmp = n[start];while (start < end) {while (n[end] >= tmp && start < end)end--;if (start < end) {n[start++] = n[end];}while (n[start] < tmp && start < end)start++;if (start < end) {n[end--] = n[start];}}n[start] = tmp;return start;}在代码中有这样一个函数:public static void quickSortSwap(int[] n, int l, int h)该函数可以实现,元素集合中特定的l到h 位置间的数据元素进行排序。
首先这个程序不是快速排序。 它是一个递归全排列生成的程序。 它是根据输入的顺序生成的。 只要你输入 CBA ,输出就是倒序的了。 你这里没说清输入的格式,所以没法作出改动。 var str:string;l:longint;f:array[1..8]of boolean;//用来记录每个字母是否用过procedure dfs(dep:longint;ans:string);vari:longint;beginif dep>l then//若l个字母都排好了就打印beginwriteln(ans);exit;end;for i:=1 to l do//检测每一个字母if f[i]=false then//若第i个字母未用过beginf[i]:=true;//标记此字母已使用dfs(dep+1,ans+str[i]);{将str第i字母选为第dep个字母,再选下一个}f[i]:=false;//返回时将已用过的字母“还掉”不用了end;end;beginreadln(str);l:=length(str);fillchar(f,sizeof(f),0);//标记每个字母都未用过dfs(1,);end.
快速排序的基本思想就是从一个数组中任意挑选一个元素(通常来说会选择最左边的元素)作为中轴元素,将剩下的元素以中轴元素作为比较的标准,将小于等于中轴元素的放到中轴元素的左边,将大于中轴元素的放到中轴元素的右边。
然后以当前中轴元素的位置为界,将左半部分子数组和右半部分子数组看成两个新的数组,重复上述操作,直到子数组的元素个数小于等于1(因为一个元素的数组必定是有序的)。
以下的代码中会常常使用交换数组中两个元素值的Swap方法,其代码如下
publicstaticvoidSwap(int[] A, inti, intj){
A[i] = A[j];
扩展资料:
快速排序算法 的基本思想是:将所要进行排序的数分为左右两个部分,其中一部分的所有数据都比另外一 部分的数据小,然后将所分得的两部分数据进行同样的划分,重复执行以上的划分操作,直 到所有要进行排序的数据变为有序为止。
定义两个变量low和high,将low、high分别设置为要进行排序的序列的起始元素和最后一个元素的下标。 第一次,low和high的取值分别为0和n-1,接下来的每次取值由划分得到的序列起始元素和最后一个元素的下标来决定。
定义一个变量key,接下来以key的取值为基准将数组A划分为左右两个部分,通 常,key值为要进行排序序列的第一个元素值。 第一次的取值为A[0],以后毎次取值由要划 分序列的起始元素决定。
从high所指向的数组元素开始向左扫描,扫描的同时将下标为high的数组元素依次与划分基准值key进行比较操作,直到high不大于low或找到第一个小于基准值key的数组元素,然后将该值赋值给low所指向的数组元素,同时将low右移一个位置。
如果low依然小于high,那么由low所指向的数组元素开始向右扫描,扫描的同时将下标为low的数组元素值依次与划分的基准值key进行比较操作,直到low不小于high或找到第一个大于基准值key的数组元素,然后将该值赋给high所指向的数组元素,同时将high左移一个位置。
重复步骤(3) (4),直到low的植不小于high为止,这时成功划分后得到的左右两部分分别为A[low……pos-1]和A[pos+1……high],其中,pos下标所对应的数组元素的值就是进行划分的基准值key,所以在划分结束时还要将下标为pos的数组元素赋值 为 key。
参考资料:快速排序算法_网络百科
内容声明:
1、本站收录的内容来源于大数据收集,版权归原网站所有!
2、本站收录的内容若侵害到您的利益,请联系我们进行删除处理!
3、本站不接受违法信息,如您发现违法内容,请联系我们进行举报处理!
4、本文地址:http://www.jujiwang.com/article/e1202a101487057780eb.html,复制请保留版权链接!

body,font,family,Arial,sans,serif,font,size,16px,line,height,1.5,h1,h2,h3,font,weight,bold,h1,font,size,24px,h2,font,size,20px,h3,font,size,18px,code,background,co...。
最新资讯 2024-09-26 23:30:44

引言NullPointerException,NPE,是Java程序中最常见的运行时异常之一,它可能导致不可预测的行为,从轻微的中断到严重的系统故障,NPE的本质在于访问一个未初始化或被显式设置为null的对象引用,理解NPE及其潜在影响对于编写稳定可靠的Java代码至关重要,NPE的成因和诊断NPE发生在以下情况下,试图调用或访问未...。
最新资讯 2024-09-26 15:11:29
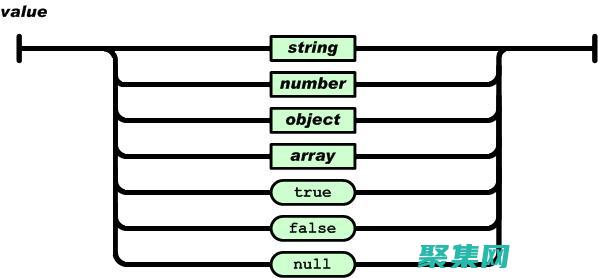
简介JSONDecode是一个Python内置函数,用于从JSON字符串解析并创建Python对象,它提供了一个便捷的方法,允许我们轻松地处理JSON数据,该数据在数据交换和存储中无处不在,函数语法```pythonjson.JSONDecodeError,msg,doc,pos,```msg,错误消息的文本描述,doc,要解析的JS...。
技术教程 2024-09-24 07:09:12
Node.js简介Node.js是一个基于ChromeV8引擎构建的跨平台JavaScript运行时环境,它使开发人员能够使用JavaScript编写服务器端应用程序,从而消除了前端和后端之间的语言障碍,全栈开发的好处全栈开发是一种软件开发方法,其中开发人员负责应用程序的完整堆栈,从前端到后端,使用Node.js进行全栈开发具有以下好...。
最新资讯 2024-09-16 11:14:06
p>,以下代码示例演示如何还原MySQL数据库,mysql,uroot,pCREATEDATABASEIFNOTEXISTSmy,restored,db,USEmy,restored,db,SOURCE,path,to,my,backup.sql,PostgreSQL数据库还原以下代码示例演示如何还原PostgreSQL数据库,p...。
最新资讯 2024-09-13 06:43:54
简介ROW函数可用于从数据表中提取特定行的数据,它还可以自动更新序号,即使在删除行之后亦是如此,此功能对于保持数据表中数据的完整性和准确性非常有用,语法```ROW,```其中,``是要提取数据的行的序号,示例假设我们有一个名为Students的数据表,其中包含以下数据,ID,姓名,年龄,1,JohnS...。
本站公告 2024-09-13 04:31:37
简介rate函数是JavaScript中一个非常有用的函数,它允许我们以每秒的帧率,FPS,执行动画,这使得创建平滑、流畅的动画变得非常容易,语法rate函数的语法如下,```rate,framesPerSecond,```其中framesPerSecond是要执行动画的帧率,FPS,基本用法要使用rate函数,我们只需要传入所需的...。
互联网资讯 2024-09-13 03:28:13

Linux定时任务Linux定时任务是一种强大的机制,允许用户安排在特定时间或定期执行任务,它通常用于自动化任务,例如备份、系统维护或其他需要在特定时间或间隔执行的任务,创建定时任务要创建定时任务,可以使用crontab命令,crontab是一个文本文件,包含要安排执行的任务列表,它可以由用户编辑,每个用户都有自己的crontab文件...。
最新资讯 2024-09-12 11:34:46
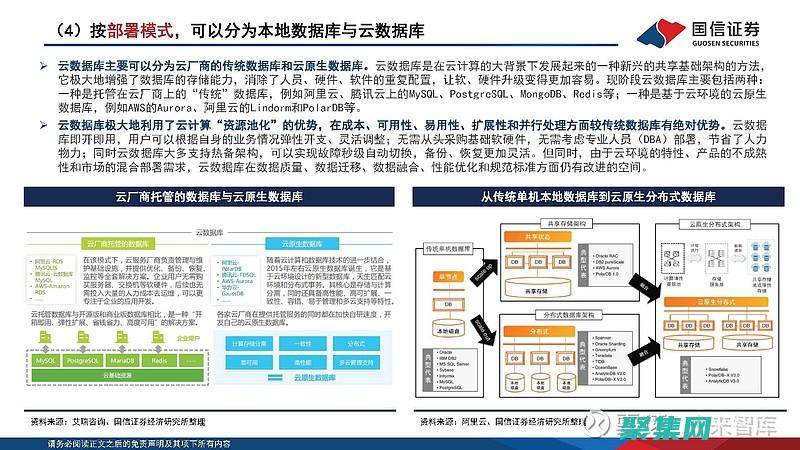
对于现代企业而言,数据库是至关重要的资产,它们存储关键数据,为组织的决策和运营提供动力,随着数据量的不断增长和复杂性的提高,企业需要创新数据库设计来保持竞争力,尖端的工具正在不断涌现,为数据库设计师提供新的方法来设计和管理数据库,这些工具可以帮助提高生产力、优化性能并确保数据的完整性,尖端数据库设计工具以下是一些最尖端的数据库设计工具...。
本站公告 2024-09-11 11:21:56

随着技术不断发展,编程语言也不断更新,为了在不断变化的就业市场中保持领先地位,掌握最热门的编程语言至关重要,在2013年,以下编程语言处于领先地位,1.PythonPython以其易学、用途广泛而闻名,在数据科学、机器学习和Web开发等领域得到了广泛应用,它的简单语法和丰富的库使开发人员能够快速有效地构建项目,Python的使用在近年...。
最新资讯 2024-09-10 15:38:18

Unix操作系统及其广泛的工具和库是一套强大的资源,可以帮助程序员编写复杂且高效的程序,通过利用Unix的功能,程序员可以创建可移植、可定制和可扩展的解决方案,本文将探讨如何充分利用Unix工具和库进行高级编程,帮助您提升编程技能并开发更出色的应用程序,引言Unix是一个多用户、多任务操作系统,它因其稳定性、可靠性和可移植性而闻名,U...。
最新资讯 2024-09-08 07:27:30

在轮回转世和灵魂不灭的观念中,借尸还魂一直是一个颇具争议的话题,近年来,随着科学技术的进步,关于灵魂轮回转世的研究也取得了一些进展,由于缺乏确凿的证据,这一领域仍然存在着诸多争论,朱秀华案件2007年,中国湖南省发生了一起震惊全国的借尸还魂案件,引发了关于灵魂轮回转世的激烈讨论,该案件的主人公名叫朱秀华,是一位来自农村的年轻女子,据家...。
互联网资讯 2024-09-05 04:31:16